Ladies and gentlemen, for our main attraction, I give you...The HELK vs APTSimulator, in a Death Battle! The late, great Randy "Macho Man" Savage said many things in his day, in his own special way, but "Expect the unexpected in the kingdom of madness!" could be our toolsmith theme this month and next. Man, am I having a flashback to my college days, many moons ago. :-) The HELK just brought it on. Yes, I know, HELK is the Hunting ELK stack, got it, but it reminded me of the Hulk, and then, I thought of a Hulkamania showdown with APTSimulator, and Randy Savage's classic, raspy voice popped in my head with "Hulkamania is like a single grain of sand in the Sahara desert that is Macho Madness." And that, dear reader, is a glimpse into exactly three seconds or less in the mind of your scribe, a strange place to be certain. But alas, that's how we came up with this fabulous showcase.
In this corner, from Roberto Rodriguez,
@Cyb3rWard0g, the specter in
SpecterOps, it's...The...HELK! This, my friends, is the s**t, worth every ounce of hype we can muster.
And in the other corner, from Florian Roth,
@cyb3rops, the The Fracas of Frankfurt, we have APTSimulator. All your worst adversary apparitions in one APT mic drop. This...is...Death Battle!
Now with that out of our system, let's begin. There's a lot of goodness here, so I'm definitely going to do this in two parts so as not undervalue these two offerings.
HELK is incredibly easy to install. Its also well documented, with lots of related reading material, let me propose that you take the tine to to review it all. Pay particular attention to the
wiki, gain comfort with the architecture, then review
installation steps.
On an Ubuntu 16.04 LTS system I ran:
- git clone https://github.com/Cyb3rWard0g/HELK.git
- cd HELK/
- sudo ./helk_install.sh
Of the three installation options I was presented with, pulling the latest HELK Docker Image from cyb3rward0g dockerhub, building the HELK image from a local Dockerfile, or installing the HELK from a local bash script, I chose the first and went with the latest Docker image. The installation script does a fantastic job of fulfilling dependencies for you, if you haven't installed Docker, the HELK install script does it for you. You can observe the entire install process in
Figure 1.
 |
| Figure 1: HELK Installation |
You can immediately confirm your clean installation by navigating to your HELK KIBANA URL, in my case http://192.168.248.29.
For my test Windows system I created a Windows 7 x86 virtual machine with Virtualbox. The key to success here is ensuring that you install Winlogbeat on the Windows systems from which you'd like to ship logs to HELK. More important, is ensuring that you run Winlogbeat with the right
winlogbeat.yml file. You'll want to modify and copy this to your target systems. The critical modification is line 123, under Kafka output, where you need to add the IP address for your HELK server in three spots. My modification appeared as
hosts: ["192.168.248.29:9092","192.168.248.29:9093","192.168.248.29:9094"]. As noted in the HELK architecture diagram, HELK consumes Winlogbeat event logs via
Kafka.
On your Windows systems, with a properly modified
winlogbeat.yml, you'll run:
- ./winlogbeat -c winlogbeat.yml -e
- ./winlogbeat setup -e
You'll definitely want to set up Sysmon on your target hosts as well. I prefer to do so with the
@SwiftOnSecurity configuration file. If you're doing so with your initial setup, use
sysmon.exe -accepteula -i sysmonconfig-export.xml. If you're modifying an existing configuration, use
sysmon.exe -c sysmonconfig-export.xml. This will ensure rich data returns from Sysmon, when using adversary emulation services from APTsimulator, as we will, or experiencing the real deal.
With all set up and working you should see results in your Kibana dashboard as seen in
Figure 2.
 |
| Figure 2: Initial HELK Kibana Sysmon dashboard. |
Now for the showdown. :-) Florian's
APTSimulator does some comprehensive emulation to make your systems appear compromised under the following scenarios:
- POCs: Endpoint detection agents / compromise assessment tools
- Test your security monitoring's detection capabilities
- Test your SOCs response on a threat that isn't EICAR or a port scan
- Prepare an environment for digital forensics classes
This is a truly admirable effort, one I advocate for most heartily as a blue team leader. With particular attention to testing your security monitoring's detection capabilities, if you don't do so regularly and comprehensively, you are, quite simply, incomplete in your practice. If you haven't tested and validated, don't consider it detection, it's just a rule with a prayer. APTSimulator can be observed conducting the likes of:
- Creating typical attacker working directory C:\TMP...
- Activating guest user account
- Adding the guest user to the local administrators group
- Placing a svchost.exe (which is actually srvany.exe) into C:\Users\Public
- Modifying the hosts file
- Adding update.microsoft.com mapping to private IP address
- Using curl to access well-known C2 addresses
- C2: msupdater.com
- Dropping a Powershell netcat alternative into the APT dir
- Executes nbtscan on the local network
- Dropping a modified PsExec into the APT dir
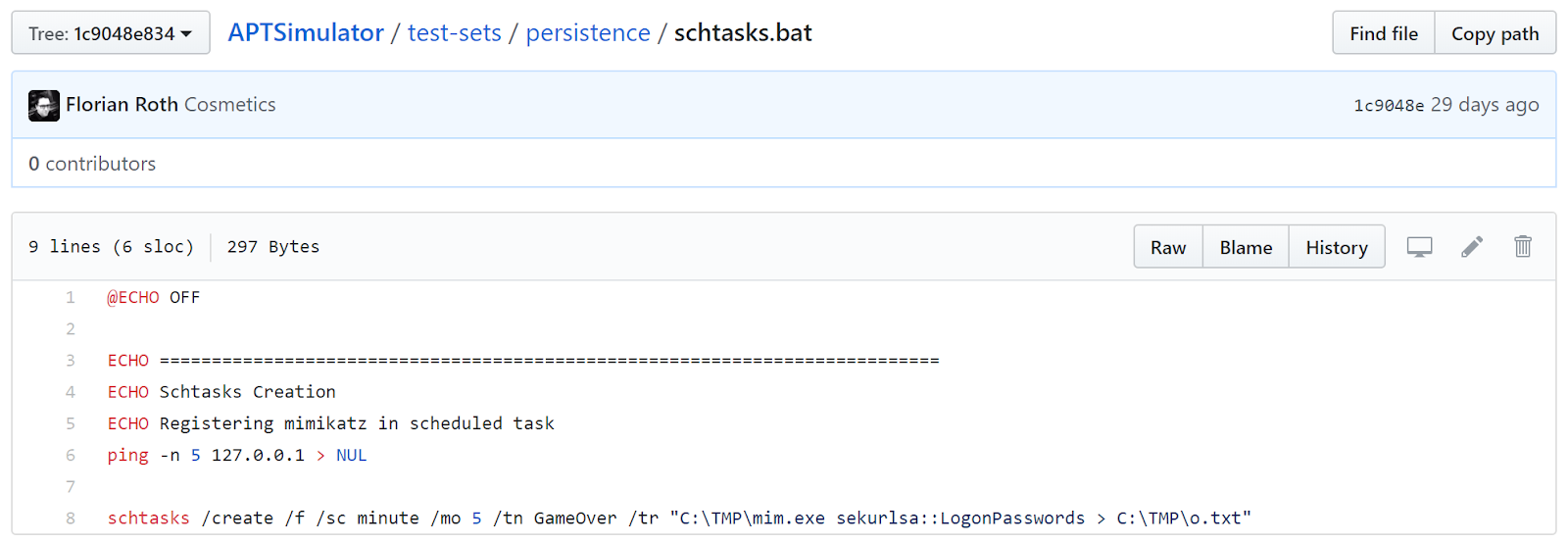
- Registering mimikatz in At job
- Registering a malicious RUN key
- Registering mimikatz in scheduled task
- Registering cmd.exe as debugger for sethc.exe
- Dropping web shell in new WWW directory
A couple of notes here.
Download and install APTSimulator from the
Releases section of its GitHub pages.
APTSimulator includes
curl.exe,
7z.exe, and
7z.dll in its
helpers directory. Be sure that you drop the correct version of 7 Zip for your system architecture. I'm assuming the default bits are 64bit, I was testing on a 32bit VM.
Let's do a fast run-through with HELK's Kibana Discover option looking for the above mentioned APTSimulator activities. Starting with a search for TMP in the
sysmon-* index yields immediate results and strikes #1, 6, 7, and 8 from our APTSimulator list above, see for yourself in
Figure 3.
 |
| Figure 3: TMP, PS nc, nbtscan, and PsExec in one shot |
Created TMP, dropped a PowerShell netcat, nbtscanned the local network, and dropped a modified PsExec, check, check, check, and check.
How about enabling the guest user account and adding it to the local administrator's group?
Figure 4 confirms.
 |
| Figure 4: Guest enabled and escalated |
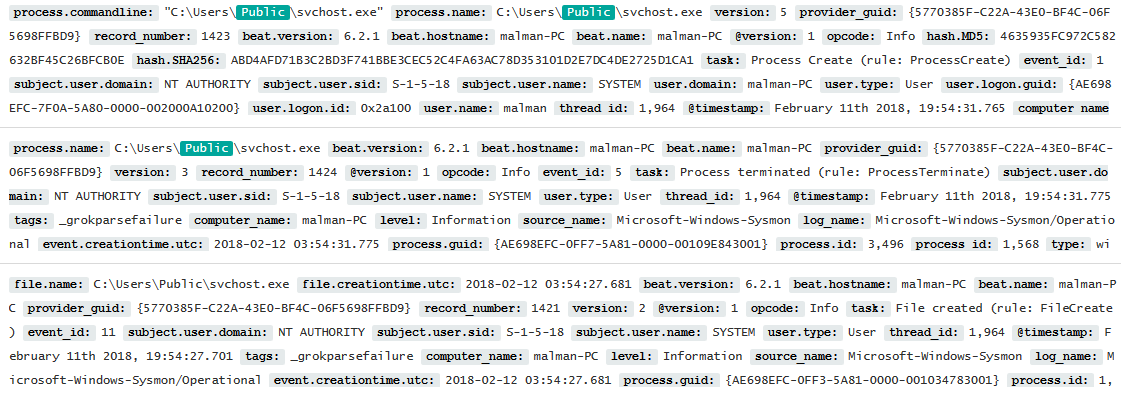
Strike #2 from the list. Something tells me we'll immediately find svchost.exe in C:\Users\Public. Aye,
Figure 5 makes it so.
 |
| Figure 5: I've got your svchost right here |
Knock #3 off the to-do, including the
process.commandline,
process.name, and
file.creationtime references. Up next, the At job and scheduled task creation. Indeed, see
Figure 6.
 |
| Figure 6. tasks OR schtasks |
I think you get the point, there weren't any misses here. There are, of course, visualization options. Don't forget about Kibana's Timelion feature. Forensicators and incident responders live and die by timelines, use it to your advantage (Figure 7).
 |
| Figure 7: Timelion |
Finally, for this month, under HELK's Kibana Visualize menu, you'll note 34 visualizations. By default, these are pretty basic, but you quickly add value with sub-buckets. As an example, I selected the Sysmon_UserName visualization. Initially, it yielded a donut graph inclusive of malman (my pwned user), SYSTEM and LOCAL SERVICE. Not good enough to be particularly useful I added a sub-bucket to include process names associated with each user. The resulting graph is more detailed and tells us that of the 242 events in the last four hours associated with the malman user, 32 of those were specific to cmd.exe processes, or 18.6% (
Figure 8).
 |
| Figure 8: Powerful visualization capabilities |
This has been such a pleasure this month, I am thrilled with both HELK and APTSimulator. The true principles of blue team and detection quality are innate in these projects. The fact that Roberto consider HELK still in alpha state leads me to believe there is so much more to come. Be sure to dig deeply into APTSimulator's
Advance Solutions as well, there's more than one way to emulate an adversary.
Next month Part 2 will explore the Network side of the equation via the Network Dashboard and related visualizations, as well as HELK integration with Spark, Graphframes & Jupyter notebooks.
Aw snap, more goodness to come, I can't wait.
Cheers...until next time.